Is My RAG System Over-Engineered? I Tested It.
Published:

Published:
Published:
Published:
Published:
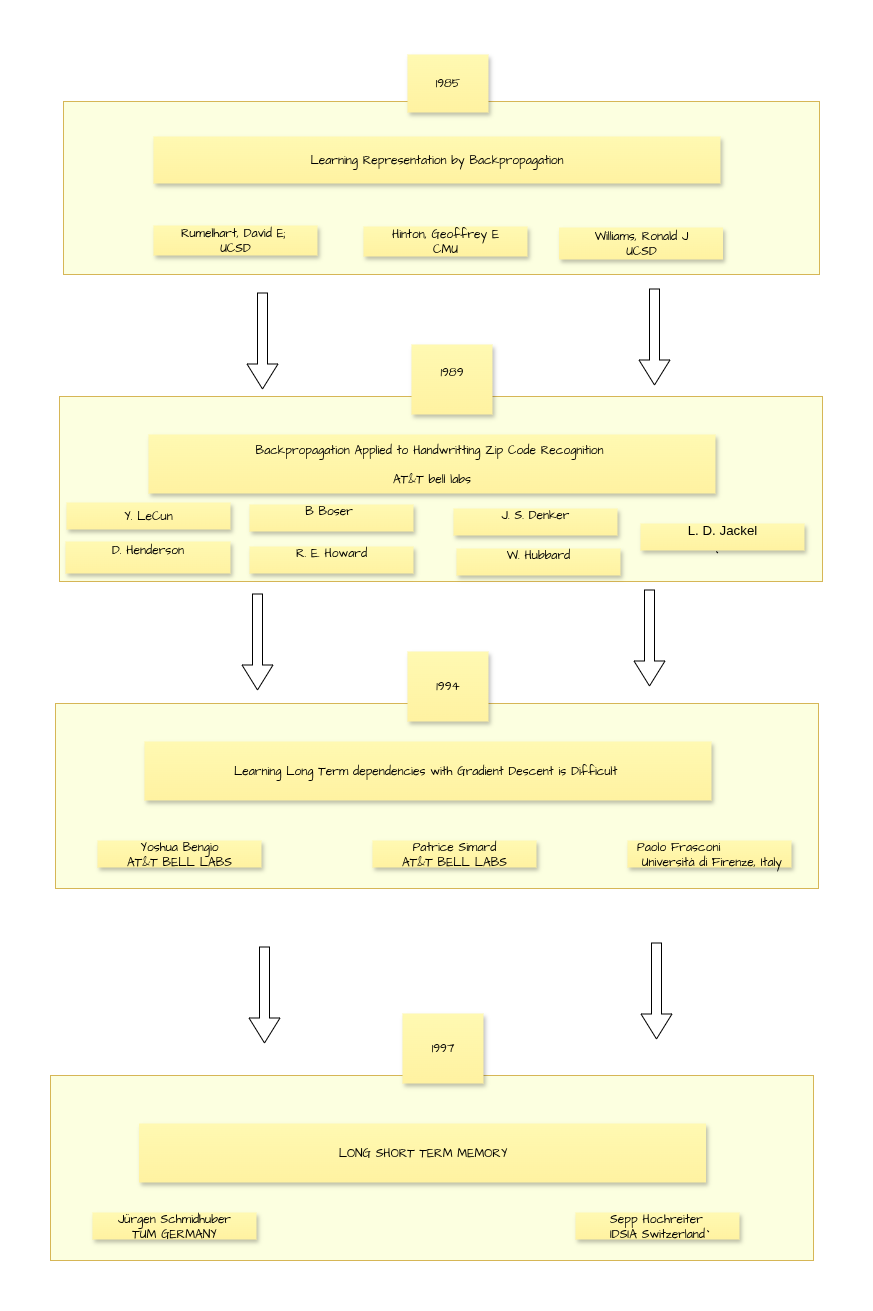
Published:
Welcome to the wonderfully wacky world of AI image generation, where noise isn’t just unwanted static—it’s the secret sauce that transforms raw data into breathtaking visuals.
If you’ve ever wondered how an algorithm goes from a garbled mess of pixels to a photorealistic masterpiece, buckle up: we’re about to diffuse some serious knowledge!
Published:
I’ve been looking into getting started with using transformers for speech. I’ve been doing some reading and attended a talk where I learned about using Hubert for the encoder in most articles.
Published:
====== I was checking out few repositories for Language translation and came across set of following keywords which got me more interested towards checking these out …
Published:
ASR, or automatic speech recognition, is a technology that aims to convert spoken utterances into a textual representation such as words, syllables, or phonemes. Speech recognition technology involves three models: the lexicon model which understands how words are pronounced, the acoustic model which analyzes speech patterns, and the language model which predicts word sequences. These models work together in decoding to produce accurate transcriptions of spoken language.
Published:
Whisper is a cutting-edge speech recognition model developed by OpenAI in October 2022. Its primary purpose is to convert audio files into text with remarkable accuracy, supporting up to 99 languages, including Japanese. The model’s encoder was trained through a technique called weakly supervised learning, leveraging a vast dataset of over 68,000 hours of speech. This approach enabled the model to surpass the accuracy of traditional academic data sets.