UNDERSTANDING Automatic Speech Recognition Technology (HUBERT) (contd.)
Published:
I’ve been looking into getting started with using transformers for speech. I’ve been doing some reading and attended a talk where I learned about using Hubert for the encoder in most articles.
So, let’s start with discovering the hidden units used for transforming speech data into a language-type data structure by representing speech as a sequence of discrete units, and then we can move on to discussing some cliche descriptions. Have you heard of deep clustering? I keep coming across some end-to-end approaches for speaker diarization.
It’s a system designed for vision models to reuse image clusters for pseudo-labeling in order to train a model in a self-supervised manner.
The main issue is the lack of labelled data and the manual annotation process for a large amount of data, which is a problem for both image and audio data. Facebook introduced this network to obtain useful general-purpose visual features with a clustering network.
Initially, they focused only on k-means, but I’ve also come across some approaches using power iteration clustering. Let’s not delve too deeply into that here.
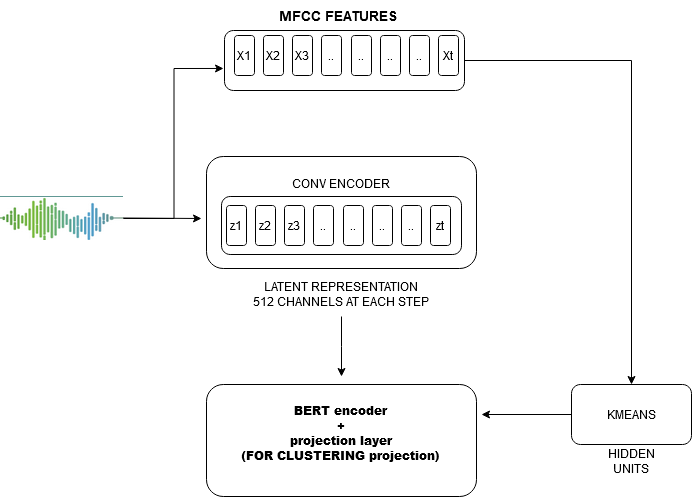
In this context, Hubert uses clustering applied to short audio segments, and the resulting clusters become the hidden units that the model aims to predict.
Hubert uses:
- Cross-entropy loss
- Builds targets using a separate clustering method rather than simultaneously learning the targets
- It reuses embeddings from the BERT encoder
An ensemble of k-means models with different codebook sizes can create targets of different grams, from vowel/consonant to senones. The convolutional waveform encoder produces a feature sequence at a 20ms frame rate for audio sampled at 16kHz (the CNN encoder down-sampling factor is 320x). The audio encoded features are subsequently randomly masked. The BERT encoder takes the masked sequence as input and produces a feature sequence [o1, · · · , oT].
Recently, a paper was published LINK by NAVER LABS Europe in France about the general-purpose multilingual Hubert model. It was trained on 90,000 hours of clean speech and utilises faiss-based clustering. Hubert has been a popular choice for multimodal language learning. This model has outperformed XLS-R and Wav2Vec2 for many machine learning tasks. They evaluated multilingual Wav2Vec 2.0 , XLSR-53, XLS-R, and MMS.
======
REFERENCES :